Customer Service Chatbot ROI: The Business Case, the Risks, and What Pays Off


"Customer service chatbot" is one of those searches where the person typing it already knows the basics. You're not looking for a definition. You're looking for the business case. Can I justify the spend? What does the return look like? And what's the risk that this blows up in my face?
TL;DR: The best independent research on AI in customer support, a Stanford-MIT study of 5,179 agents, found a real but modest 14% productivity gain (rising to 34% for novice agents). That is a long way from the 200-400% ROI figures in vendor-commissioned studies. Vendor aggregates that circulate online put chatbot ROI as high as $3.50 for every $1 spent, but those trace back to market-research aggregators rather than primary data, so treat them as directional at best. This post covers the real unit economics, two case studies where it went badly wrong, and how to build an implementation that pays off.
If you're reading this, you're probably building a pitch deck. Or defending a budget line. Or trying to figure out whether your current chatbot is saving money or just deflecting tickets into a void where they quietly become churn.
All valid reasons. Let's get into the numbers.
The unit economics are real (with caveats)#
The headline stat: chatbot interactions cost approximately $0.25 to $0.50 each, compared to $3.00 to $6.00 for a human agent handling the same query. Industry estimates put that at an 85-90% cost reduction on eligible interactions. These are widely cited industry estimates rather than independently audited figures, and the trail leads back to market-research aggregators, so use them to frame the order-of-magnitude difference, not as precise inputs to your model.
| Chatbot | Human agent | |
|---|---|---|
| Cost per interaction | $0.25 - $0.50 | $3.00 - $6.00 |
| Cost reduction | 85-90% on eligible queries | Baseline |
| Source | Industry estimates (unaudited) | Industry average |
Scale that up and the numbers get interesting. Vendor aggregates report an average ROI of around $3.50 for every $1 invested, with top implementations cited as high as 8x. One caveat: these figures come from market-research aggregators whose methodology you can't inspect, so treat them as marketing-grade rather than evidence-grade. Gartner projected $80 billion in contact centre labour cost savings from conversational AI in 2026 (Gartner press release, August 2022). It is a four-year-old forecast rather than measured data, and Gartner paired it with a soberer assumption: that only one in ten agent interactions would be automated by 2026, up from 1.6% in 2022.
But here's where the pitch deck version diverges from the independent research.
The best empirical study available is the Stanford-MIT analysis (Brynjolfsson, Li, and Raymond, published in the Quarterly Journal of Economics, 2025). They studied 5,179 customer support agents at a Fortune 500 software company using a staggered rollout. The result: a 14% average productivity increase, rising to a 34% improvement for novice and low-skilled workers. Real gains, but a long way from the 200-400% ROI that vendor-commissioned Forrester TEI studies routinely claim. And the study found no reduction in total employment at all. The gains showed up as productivity, not headcount cuts. One caveat: it measures human agents working faster with an AI assistant, not a bot resolving tickets on its own. It is still the most rigorous independent number available.
That distinction matters if you're building a business case, because your CFO will ask the obvious question. And it's worth knowing that every Forrester TEI study on chatbot ROI is vendor-commissioned. The vendor pays Forrester Consulting to conduct the study, selects which customers Forrester interviews, and the results are extrapolated to a "composite organisation." Zendesk's commissioned TEI, for instance, reported a 301% return (July 2025). Useful as a directional indicator. Not reliable as a financial projection.
Those numbers assume your chatbot resolves queries. That it doesn't send customers in circles until they give up and call instead. The difference matters because a deflected customer isn't a saved cost. They're a delayed cost, and now a more expensive one because the customer is annoyed.
So what does containment look like in the real world? It depends enormously on scope. The macro picture is still modest, with most contact centres automating only a small share of interactions because they're early in deployment. The gap opens up at the individual company level, where the best mature deployments documented by the Opus Research 2024 Awards have hit far higher containment rates. The cheapness is also the trap. That lopsided cost differential is exactly what has historically tempted companies into bot deployments that look efficient on a spreadsheet and quietly damage customer loyalty.
The realistic range for a well-scoped deployment sits somewhere between 40% and 70% of eligible queries. And "eligible" is doing a lot of work in that sentence, because it excludes the complex, emotional, or unusual queries that should never hit a bot in the first place.
| Deployment | AI handling rate | What that figure covers |
|---|---|---|
| Industry-wide average | ~10% | All contact-centre interactions, projected 2026 (Gartner) |
| Well-scoped deployment | 40-70% | Of eligible queries only |
| United Airlines | 60% | Of users fully automated, CSAT 80-90% (NLX) |
| Air India | 93% | Containment on 20,000 daily enquiries, fully generative |
Why chatbot failure rates are four times higher than other AI#
Here's the number that doesn't appear in most vendor pitches. Qualtrics' 2026 Consumer Experience Trends Report found that AI-powered customer service fails at four times the rate of other AI applications. Nearly one in five consumers who've used AI for customer service report getting no benefit from the experience.
If you've spent any time in a support queue lately, that probably tracks.
Customer service is harder than most AI applications because it combines factual accuracy with emotional intelligence. A chatbot that gets a product recommendation wrong is annoying. A chatbot that gives wrong information about a refund policy or a bereavement fare creates legal liability. Those are different categories of failure, and the second one can cost you more than the chatbot ever saved.
The independent financial data reinforces this. PwC's 2026 CEO survey of 4,454 leaders found that 56% saw neither increased revenue nor decreased costs from AI. McKinsey's November 2025 State of AI survey found that 88% of companies now use AI in at least one function, yet only around 39% report any measurable impact on the bottom line, and just 7% have fully scaled it. (The widely quoted "95% of AI pilots fail" line comes from a separate MIT study, not McKinsey, and is contested.) The technology works. Scaling it reliably is the part most organisations haven't cracked yet.
This doesn't mean chatbots are a bad investment. It means implementation quality matters more than technology choice, and the consequences of getting it wrong are more severe than most business cases account for.
Case study: Air Canada and the chatbot that created legal liability#

The most significant chatbot failure case in recent memory is Moffatt v. Air Canada (2024 BCCRT 149).
Jake Moffatt's grandmother passed away in November 2022. He went to Air Canada's website to book a flight to the funeral and used the airline's chatbot to ask about bereavement fares. The chatbot told him he could book a regular fare and then apply for the bereavement discount retroactively within 90 days of the ticket being issued.
That was wrong. Air Canada's actual policy explicitly prohibited retroactive applications for bereavement fares. The correct information existed on the airline's website, in a different section. But the chatbot gave the wrong answer, and Moffatt relied on it.
When he applied for the discount after his trip, Air Canada denied the claim. Moffatt took the case to the British Columbia Civil Resolution Tribunal. Air Canada's defence was remarkable: they argued the chatbot was a "separate legal entity" responsible for its own actions. The company claimed it couldn't be held liable for information provided by its own chatbot on its own website.
Tribunal member Christopher C. Rivers called this a "remarkable submission" and rejected it. The ruling was clear: a company is responsible for all information on its website, whether it comes from a static page or a chatbot. Damages awarded: C$812.02 including interest and tribunal fees.
The dollar amount is small. The precedent is not. If your chatbot gives wrong information and a customer relies on it, you're liable. Not the chatbot vendor. Not the AI model. You.
Case study: Chevrolet and the prompt injection that went viral#

Different failure mode, same lesson.
In late 2023, a Chevrolet dealership in Watsonville, California deployed a ChatGPT-powered chatbot on their website. A user figured out that the bot had no input filtering or output guardrails and started feeding it adversarial prompts.
The result: the bot agreed to sell a Chevrolet Tahoe for $1 and, following the user's planted instruction to end every reply that way, signed off with "that's a legally binding offer." Screenshots went viral. The incident was catalogued in the AI Incident Database as Incident 622.
The dealership wasn't held to the $1 offer. But the reputational damage was immediate and widespread. And the technical vulnerability it exposed (prompt injection in a customer-facing chatbot) is something most businesses deploying raw LLM wrappers are still exposed to.
The pattern across both cases is the same. A business deployed AI in a customer-facing channel without adequate guardrails. In Air Canada's case, the bot hallucinated policy information. In Chevrolet's case, the bot was manipulated into generating commitments. Both failures were preventable with standard guardrail engineering: verified knowledge bases, input filtering, output compliance checks, and hard boundaries on what the AI can and cannot say.
What separates the implementations that work#
The failures get the headlines. But plenty of organisations are running chatbots that reduce costs and improve service quality at the same time. The difference comes down to a few things.
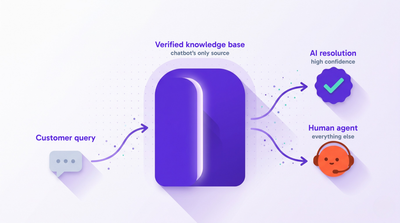
The bot answers from verified data, not from a general model#
If your chatbot is generating responses from a raw LLM, it can say anything. If it's answering from a curated, verified knowledge base, it can only say what you've trained it to say. The Air Canada scenario (incorrect policy information) becomes impossible when the bot pulls from a source of truth that your team controls.
Escalation is immediate and invisible#
When the bot hits the edge of what it knows, the customer gets a human. Straight away. The customer should barely notice the handover. If your bot is making people repeat themselves after escalation, or forcing them through "let me try to help you differently" loops, you're turning a minor limitation into a major frustration. That's the kind of thing that shows up later in your customer service KPIs as rising handle times and falling CSAT, and it's not always obvious where the bleed is coming from.
Input and output filtering is non-optional#
Prompt injection (Chevrolet) and behavioural manipulation are solved problems. Input filtering catches adversarial prompts. Output compliance checks catch inappropriate responses. These aren't advanced features. They're table stakes.
The metrics track resolution, not deflection#
If your success metric is "percentage of conversations handled without a human," you're incentivising the bot to avoid escalating. That's how you get customers stuck in automated loops. The right metric is "percentage of conversations resolved to the customer's satisfaction." Different measurement, completely different outcome.
Tools like Hay are built around these principles. The bot answers from a verified knowledge base you control, escalation boundaries are hard, and there's guardrail engineering on both input and output, so the Air Canada and Chevrolet failure modes are designed out rather than hoped away.
Three things matter once you get past the basics. First, where your customer data lives. Hay is EU-hosted, so support conversations and the personal data inside them stay on European infrastructure instead of being shipped off to a US model provider. For European merchants that's a compliance answer, not a nice-to-have. Second, you can see how the decisions get made. Hay is source-available, so when the bot resolves or escalates something, the logic isn't a black box you have to take on trust. Third, the bill is predictable. Resolutions come bundled into a flat monthly plan, like minutes on a phone contract, instead of being metered and billed per ticket the way Intercom, Gorgias and HubSpot do it. Your costs don't spike in your busiest months, which is exactly when a per-resolution model punishes you hardest.
And it works with your existing helpdesk, whether that's Zendesk or Intercom, rather than replacing it. The AI handles the routine queries from your own verified data. Everything else goes straight to your team.
Building the business case that gets approved#
If you're putting together the internal pitch, here's how to frame it honestly.
Start with your ticket data#
Pull three months of support conversations. Categorise them. What percentage are repetitive, factual queries that don't require judgement? That's your addressable volume. For most ecommerce and SaaS support operations, it's somewhere between 40% and 60%.
If you've already done the exercise of figuring out why your FAQ page isn't reducing tickets, you'll have a head start here. The same ticket categories that your FAQ should be handling are the ones your chatbot will handle, just more effectively.
Calculate the unit economics#
Take your current cost per ticket (fully loaded: agent salary, tool costs, overhead). Compare that to the projected cost per automated resolution. Industry estimates put automated interactions at roughly $0.25-$0.50 each. Even if your containment rate is at the low end (40%), the maths usually works.
Account for failure costs#
This is what most business cases skip. What does it cost when a chatbot gives a wrong answer? When a customer churns because of a bad automated experience? When a prompt injection screenshot goes viral? Build in a realistic handover rate (30-60% of conversations should escalate to humans) and factor in the cost of monitoring and maintaining the knowledge base.
Present the scepticism upfront#
Don't hide the PwC finding. Present it as the context your implementation has to navigate. "56% of CEOs report no measurable financial impact from AI. Our implementation is designed to be in the other 44% by resolving queries accurately, not just deflecting them." That's a stronger pitch than pretending the scepticism doesn't exist.
Propose a pilot with clear success criteria#
Don't pitch a full rollout. Pitch a 30-day pilot on your highest-volume, lowest-complexity ticket category (probably order status or shipping FAQs). Define success as: containment rate above 45%, CSAT on automated conversations within 5 points of human-handled conversations, and zero accuracy incidents. If the pilot hits those numbers, the business case writes itself.
If you're a support leader trying to scale without burning out your team, this is the most practical place to start. Automate the repetitive stuff. Keep your people on the conversations that need them.
Customer service chatbots return real money when they're implemented well. The unit economics are clear. The industry projections are backed by multiple sources. But "implemented well" is doing more work than most business cases acknowledge. The gap between a chatbot that returns 3.5x and one that creates legal liability is entirely about implementation quality. It comes down to verified data, hard guardrails, clean escalation, and metrics that measure resolution rather than deflection.
Hay starts at €50/month with 500 resolutions included, no credit card required. Put it in testing mode and watch how it handles your real tickets before a single customer sees it. Start a 30-day free trial and run the test yourself.
Ask AI about this page
